Memoryless and Memory-Enabled Decision Systems
The score-memory idea in PLE-DR kept bothering me after I wrote it down. Not because it felt wrong, but because it felt small — like a local trick for docking pipelines when it might be an instance of something much larger. So I want to try defining that larger thing as bluntly as I can and see what falls out.
Note: This is not an xkcd comic, and is not affiliated with or created by xkcd. It is an illustration inspired by xkcd's visual style, created using ChatGPT.
Start with the simplest possible distinction.
Two Kinds of System
A memoryless decision system makes each decision solely from current information, and then forgets.
Input
↓
Decision
↓
Forget
Examples are everywhere once you look: a single docking-score cutoff, a knockout tournament, a stateless API, a one-time jury verdict, a reflex. The appeal is real — these systems are fast, cheap, and scalable. They have exactly one serious weakness, and it is fatal in the wrong setting:
In a memoryless system, early mistakes are permanent.
A memory-enabled system lets past evidence survive and influence what comes next.
Input
↓
Decision
↓
Store evidence
↓
Future decisions influenced
The immune system does this. So does a credit history, the scientific literature, human expertise — and the score-memory protocol from the last note. These systems are robust to noise, can learn from mistakes, and can recover opportunities they nearly missed. They pay for it with complexity, and with a darker liability: they can preserve bad information as faithfully as good information.
That trade is the whole subject. The interesting question is not which kind is better — it is how much is the memory worth, and when.
The Quantity I Actually Care About
Define memory value as
$V_m$ — how much better a system performs when historical information is retained, holding everything else fixed.
I want to resist the temptation to leave this as a slogan. It is the same mistake consensus docking makes with disagreement: gesturing at a thing instead of measuring it. So before generalising to evolution and civilisations, I forced myself to compute $V_m$ in the one domain I can actually control — virtual screening.
A Small Experiment
The setup is deliberately synthetic, so the mechanism is visible rather than buried in real chemistry. Six thousand compounds, each with a hidden true binding quality. Four docking engines each observe that quality through their own noise — the projection problem from the last note, made into a knob. The genuinely best ~120 compounds are the “true hits” we would like to keep.
Two pipelines compete:
- Memoryless cascade — the classic funnel. Each stage ranks the survivors by one engine and irreversibly discards the bottom fraction. A hit that one early engine happens to mis-score is gone, regardless of what later engines would have said.
- Memory-enabled — retain every compound’s full score history, discard nothing outright, and rank by an uncertainty-aware aggregate: $\mathrm{mean}(\mathrm{scores}) + \lambda \cdot \mathrm{std}(\mathrm{scores})$. The $+\mathrm{std}$ term is the revisit rule from PLE-DR — a compound the engines disagree about is given the benefit of the doubt rather than thrown away.
The Math Behind the Toy Model
The simulation starts by assigning each compound $i$ a latent binding quality
\[q_i \sim \mathcal{N}(0, 1), \qquad i = 1,\ldots,N\]with $N = 6000$. The true hits are the $H = 120$ compounds with the largest hidden quality:
\[\mathcal{H} = \operatorname{Top}_{120}(q_i).\]Each of the $K = 4$ docking engines observes that same hidden quality through noise:
\[s_{ik} = q_i + \sigma e_{ik},\]where $\sigma = 1$ in the figures. To control whether the engines make independent mistakes or share the same bias, the error term is built from a shared component and a private component:
\[e_{ik} = \sqrt{\rho}\,z_i + \sqrt{1-\rho}\,\eta_{ik},\]with
\[z_i \sim \mathcal{N}(0, 1), \qquad \eta_{ik} \sim \mathcal{N}(0, 1).\]So $\rho = 0$ gives independent engine errors, while $\rho = 1$ makes every engine inherit the same error for a compound. Because the two noise terms are scaled by $\sqrt{\rho}$ and $\sqrt{1-\rho}$, the total error variance stays fixed while the cross-engine correlation changes.
The memoryless cascade begins with all compounds, $S_0 = {1,\ldots,N}$, then keeps only a fixed fraction after each engine:
\[S_t = \operatorname{Top}_{\lfloor f_t |S_{t-1}| \rfloor} \left(\{s_{ik_t}: i \in S_{t-1}\}\right),\]with
\[(f_1, f_2, f_3) = (0.35, 0.30, 0.30).\]Anything outside $S_t$ is permanently discarded. The memory-enabled pipeline instead assigns every compound an aggregate score
\[a_i = \bar{s}_i + \lambda \sigma_i^{(s)},\]where
\[\bar{s}_i = \frac{1}{K}\sum_{k=1}^{K}s_{ik},\]and
\[\sigma_i^{(s)} = \sqrt{\frac{1}{K}\sum_{k=1}^{K}(s_{ik} - \bar{s}_i)^2}.\]In the plotted experiment, $\lambda = 0.5$. The first term rewards high average predicted quality; the second rewards disagreement enough to keep uncertain compounds from vanishing too early.
For any final shortlist size $L$, recall is
\[\operatorname{Recall@}L = \frac{|\operatorname{Top}_{L}(\text{ranked list}) \cap \mathcal{H}|}{|\mathcal{H}|}.\]The memory value is the absolute recall gain from retaining score history:
\[V_m(L,\rho) = \operatorname{Recall@}L_{\mathrm{memory}} - \operatorname{Recall@}L_{\mathrm{memoryless}}.\]For the correlation sweep, I fixed $L = 300$, evaluated $\rho \in {0, 0.1,\ldots,1.0}$, and averaged over 40 random replicates. The band in the figure is the 16th to 84th percentile range across those replicates.
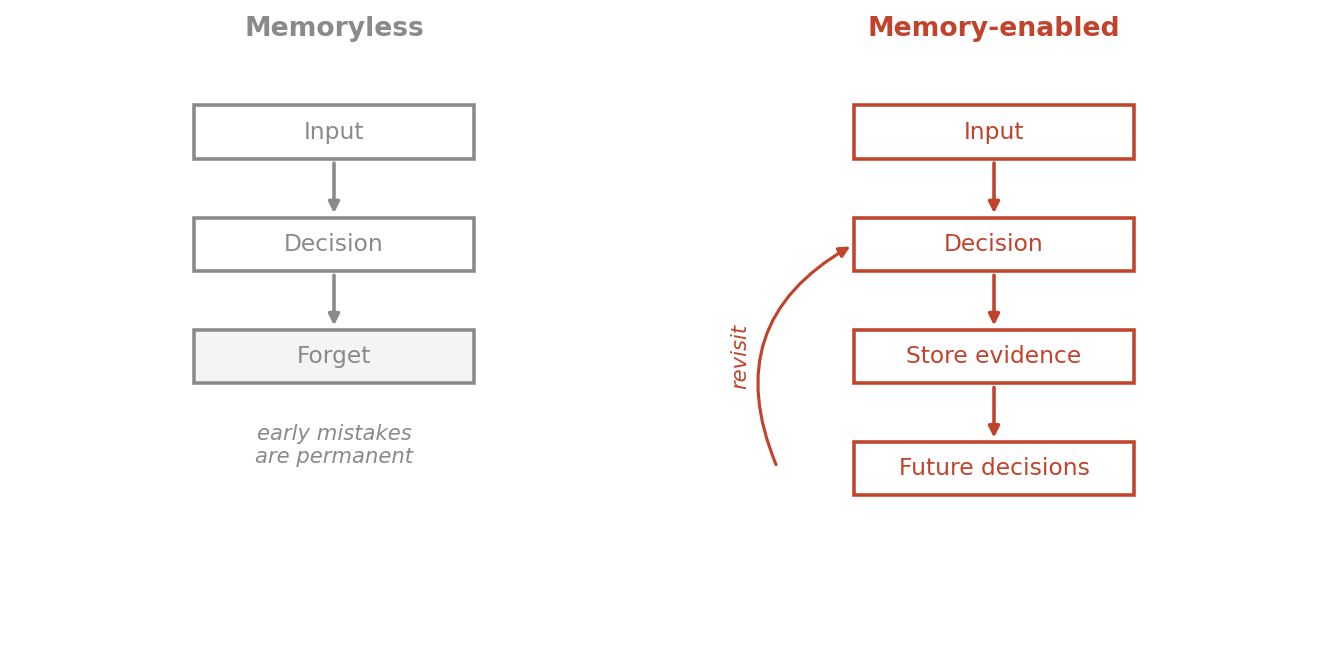
Then I measure recall: of the true hits, how many does each pipeline keep in a final shortlist of size $L$?
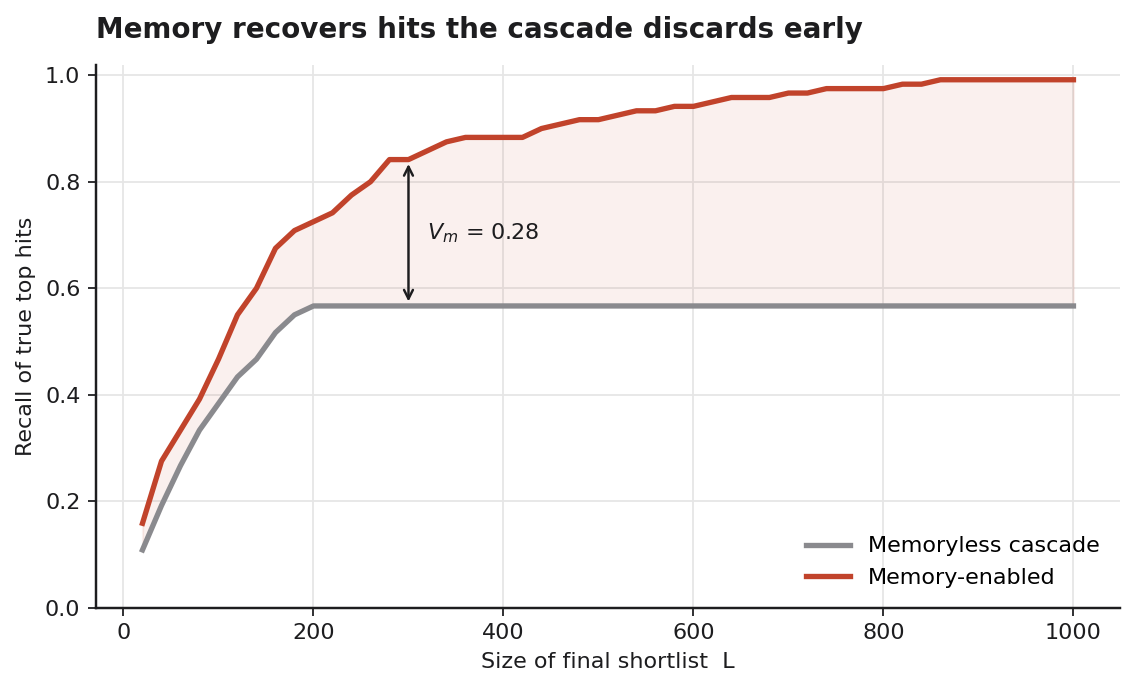
The shape is the entire argument. The memoryless cascade climbs, then plateaus near 0.57 and stops — widening the shortlist past ~200 buys nothing, because the hits it discarded in round one cannot be recalled by any later round. “Early mistakes are permanent” is not a metaphor here; it is the flat line. The memory-enabled pipeline keeps climbing to 0.92, because nothing was ever truly thrown away. At a shortlist of 300 the gap is $V_m \approx 0.28$ — the memory pipeline recovers roughly half again as many real hits for the same experimental budget.
That is a satisfying result, but on its own it is a sales pitch. The honest question is when memory stops being worth it.
When Memory Stops Paying
I made the engines’ errors correlated by a factor $\rho$ — at $\rho = 0$ they fail independently, at $\rho = 1$ they all make the same mistakes (a shared systematic bias, the “preserve bad information” failure made concrete) — and recomputed $V_m$.
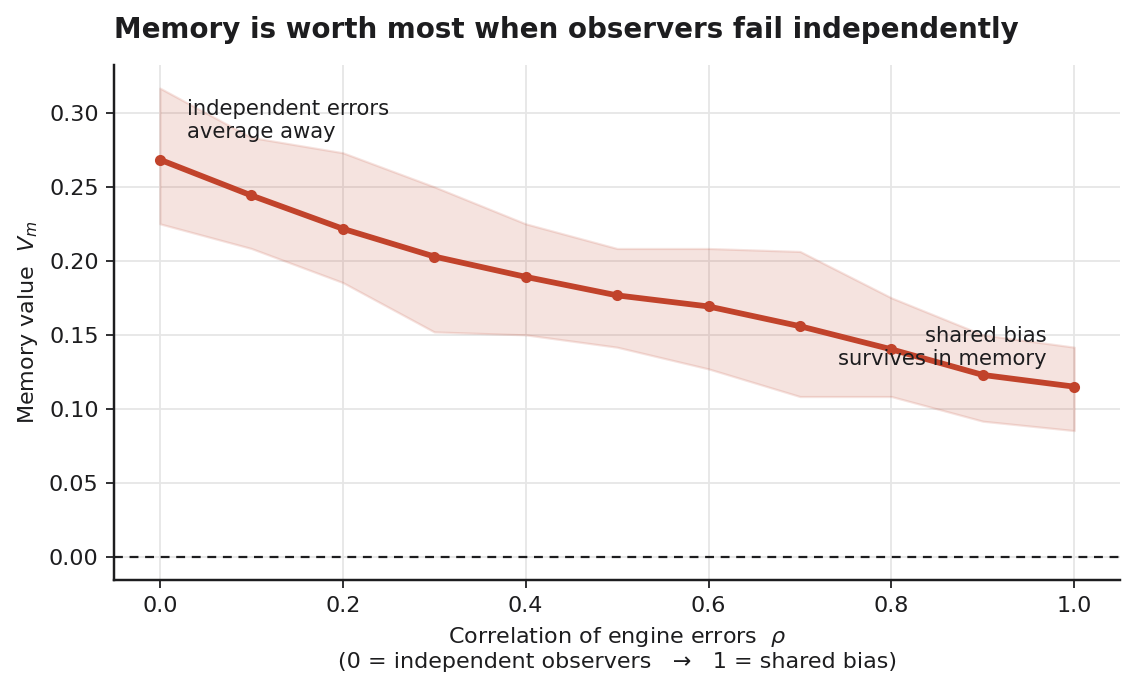
$V_m$ falls steadily, from about 0.27 with independent observers to about 0.12 when they share a bias — it loses more than half its value. This is the same thesis as the disagreement note, now stated as a quantity: memory is worth most precisely when your observers fail independently, because then their private errors average away and only the signal accumulates. When they err together, there is nothing for the accumulation to cancel.
But notice what $V_m$ does not do: it does not reach zero. Even with fully shared bias, retaining information beats forgetting it. That surprised me, and the reason is worth stating because it corrects my own first draft of this idea. Memory’s value has two components, not one:
- Noise-averaging — repeated independent observations cancel their private errors. This part does vanish as observers become correlated.
- Reversibility — never discarding means an early misjudgement is never final. This part has nothing to do with independence, and it persists even under shared bias.
I had assumed memory could be made harmful simply by feeding it bad information. The experiment says otherwise: a shared artifact corrupts the cascade too — it was exposed to the same bad engines — so memory’s relative advantage survives. To make forgetting actually preferable you need an asymmetry: a contaminated channel that the memory system trusts but the cascade structurally avoids. That regime exists, but it has to be engineered; it is not the default. The plain statement “memory can preserve bad information” is true, but it does not by itself imply “memory is worse.” That is a sharper claim than I started with, and I trust it more for having had to find it.
The Same Pattern, Larger
With $V_m$ defined as information from past states that influences future decisions, the broad cases stop being loose analogies and start looking like the same mechanism at different scales — though each deserves its own caution.
Evolution is the cleanest. Natural selection is not memoryless: genes are memory, a compressed record of which past environments rewarded which configurations. Strip out inheritance and you get selection with a Forget step — variation that never compounds. Selection without memory barely climbs, for the same reason the cascade’s recall plateaus.
Science is civilisation’s literature acting as durable storage. If every paper vanished on publication, each generation would re-derive from scratch; the compounding that makes science cumulative is exactly the Store-evidence arrow.
Institutions — constitutions, precedent, case law — are collective memory, which is one honest way to read the difference between a system with accumulated precedent and a pure direct democracy deciding each question fresh. (Here the second component bites: institutions also preserve bad precedent faithfully, which is the cost side of $V_m$ made political.)
Machine learning sharpens it. A feed-forward network is largely memoryless at inference; an RNN carries a hidden state forward; a transformer’s attention is, read plainly, a memory- retrieval mechanism over the context. The trajectory of the field has been, in part, a steady purchase of larger and more flexible $V_m$.
I want to be careful not to over-claim the unification. These systems differ in what counts as “evidence,” in how faithfully it is stored, and in whether the bad-information cost dominates. The pattern is a lens, not a theorem.
The Distinction Underneath
Still, the lens suggests a reframing I keep coming back to. Maybe the sharp line is not
intelligent vs unintelligent
but
memory-enabled vs memoryless
— because much of what we call intelligence appears exactly when a system can accumulate information across time and let it bear on the next decision. Two civilisations, one that forgets each generation and must rediscover fire, agriculture, mathematics, and one that preserves; the second’s advantage is not raw cleverness. It is $V_m$.
Which brings the whole thing back to where it started. A docking cascade is just one memoryless system among many, and most screening pipelines are memoryless by unexamined default. The case for building them otherwise is not that memory is always good — the second figure is precisely a map of when it is not. The case is narrower and, I think, more defensible: when your observers are imperfect and disagree independently, the information you would otherwise discard is worth more than the simplicity you would gain by discarding it. That is a measurable claim. $V_m$ is the measurement.
That is where I’d start digging.
What This Is Not
This is a toy. The compounds are synthetic, the engines are Gaussian noise rather than real scoring functions, and the recall numbers are properties of the simulation, not of any actual screen. The experiment demonstrates a mechanism — why retaining evidence recovers hits that irreversible filtering loses, and how that value scales with observer independence — but it does not establish the size of $V_m$ for any real campaign. Measuring $V_m$ on a genuine library, with real engines and experimental confirmation, is the obvious and harder next step.
Enjoy Reading This Article?
Here are some more articles you might like to read next: